R을 이용해 Data처리를 하다보면 특정 Pattern을 기준으로 문자열을 나누어야 할 경우가 있습니다.
그 기능을 str_split()을 이용해 처리할 수 있습니다.
해당 함수는 stringr 패키지에 들어있는 함수이므로 코드 실행전에 해당 패키지를 설치해 주어야 합니다.
toy example은 아래의 data를 사용하겠습니다.
install.packages(stringr)
library(stringr)
a <- data.frame(col1=c("a_b_1","c_d_1","e_f_1"), col2=c(1,2,3))
str_split함수의 인자는 다음과 같습니다.
str_split(string, pattern, n = Inf, simplify = FALSE)
string : 벡터형 data를 input으로 받습니다.
pattern : 나누고자 하는 pattern을 지정하여 넣어줍니다.
n : 나누고 싶은 갯수를 지정해 줍니다 (Default : Inf)
simplify : 문자 벡터의 리스트형으로 반환할것이냐, 문자 matrix로 반환할 것이냐를 정해줍니다 (Default : F)F 문자 벡터의 리스트형, T 문자 matrix
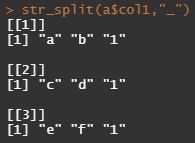
해당코드의 결과가 아래처럼 나오는 것을 볼 수 있습니다.
str_split(a$col1,"_")
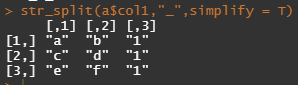
str_split(a$col1,"_",simplify = T)

simplify인자를 True로 설정을하면 위와같이 matrix형태로 return이 됩니다.
여기서 추가로 더 나아가서 str_split을 이용해 나눈 data를 기존의 data에 추가하는 것을 해보겠습니다.
simplify를 False로 했을때는 sapply함수를 이용해 리스트에서 원하는 위치에 있는 data를 가져올 수 있습니다.
c <- sapply(str_split(a$col1,"_"),"[",1)
a$col3<- c
a

sapply함수를 이용해 list를 인자로 받아 원하는 위치에 있는 data를 가져올 수 있습니다.
그리고 새로운 column에 해당 data를 넣어주면 됩니다.
simplify를 True로 했을때는 아주 간단합니다.
d <- str_split(a$col1,"_",simplify = T)
d
e <- d[,3]
a$col4<- e
a
matrix로 반환되는 data에서 원하는 위치의 data를 슬라이싱해와서 새로만든 column에 data를 넣으면 됩니다.

'R' 카테고리의 다른 글
| R ) dplyr 패키지 살펴보기 ( filter, select, arrange, mutate, summarise, group_by, %>% (파이프연산자) ) in r -2 (1) | 2021.09.02 |
|---|---|
| R ) dplyr 패키지 살펴보기 ( filter, select, arrange, mutate, summarise, group_by, %>% (파이프연산자) ) in r (1) | 2021.09.01 |
| R ) 데이터(data) 전반적 구조 파악하기 head, tail, View, dim, str, summary in r (1) | 2021.08.31 |
| R ) CSV 파일 불러오기 read.csv in r (0) | 2021.08.29 |
| read_excel로 외부 Data 불러오기 in r (0) | 2021.08.22 |




댓글