R에서는 read_excel로 위부 Data를 불러와 가공을 할 수 있습니다.
이에 대해 알아보려고 합니다.
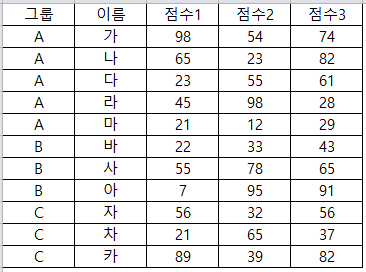
위의 DATA를 이용하여 해보겠습니다.
read_excel을 사용하려면 해당기능을 제동하는 패키지를 설치해주어야 합니다.
install.pakages("readxl") *l은 소문자 L
library(readxl)
data <- read_excel("C:/Users/user/Desktop/R블로그/read excel, read csv/RAW DATA.xlsx")
data
read_excel에는 여러 인자가 있지만 먼저 옵션을 정하지 않고 불러와 보겠습니다.
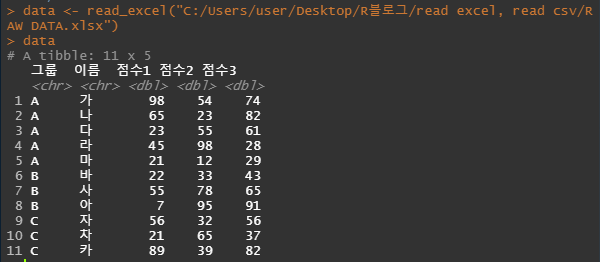
위와 같이 data가 불러와졌습니다.
이제 read_execl의 여러 인자에 대해서 알아보겠습니다.
read_excel(
path,
sheet = NULL,
range = NULL,
col_names = TRUE,
col_types = NULL,
na = "",
trim_ws = TRUE,
skip = 0,
n_max = Inf,
guess_max = min(1000, n_max),
progress = readxl_progress(),
.name_repair = "unique")
path : 불러올 파일의 경로와 파일명을 입력합니다.
sheet : 해당 파일에서 불러올 sheet를 선택할 수 있습니다.

2번째 시트에 위와 같은 data를 입력하고
data2 <- read_excel("C:/Users/user/Desktop/R블로그/read excel, read csv/RAW DATA.xlsx",sheet=2)
data2

sheet인자에 2를 입력해주면 2번째 sheet의 data를 불러옵니다.
range : 불러올 data의 범위를 지정해 줄 수 있습니다.
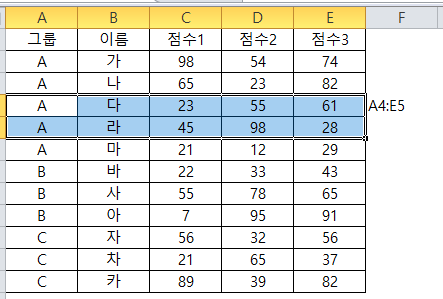
data3 <- read_excel("C:/Users/user/Desktop/R블로그/read excel, read csv/RAW DATA.xlsx",sheet=1,range="A4:E5") data3

col_names : 열의 이름을 지정할 수 있습니다.
해당 인자를 입력하지 않으면 행의 첫줄이 열의 이름으로 들어가며 모두 data로 쓰고 싶다면 "F"를 입력하면 됩니다
data4 <- read_excel("C:/Users/user/Desktop/R블로그/read excel, read csv/RAW DATA.xlsx",sheet=1,col_names=F)
data4
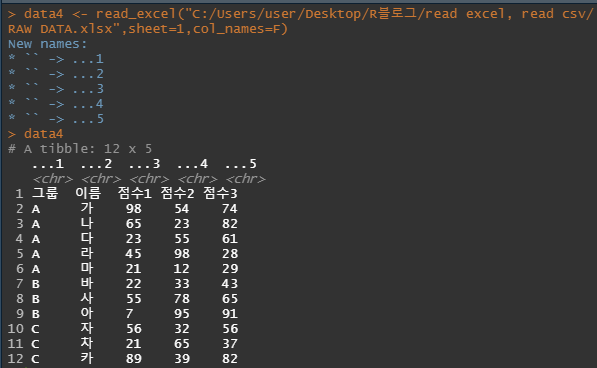
col_types : column의 data형식을 정할 수 있습니다.
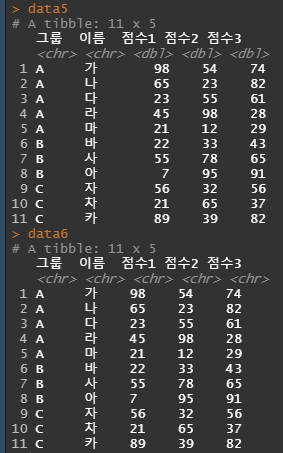
data5 <- read_excel("C:/Users/user/Desktop/R블로그/read excel, read csv/RAW DATA.xlsx",sheet=1)
data6 <- read_excel("C:/Users/user/Desktop/R블로그/read excel, read csv/RAW DATA.xlsx",sheet=1,col_types=c("text","text","text","text","text"))
data5
data6
data5의 점수 column은 dbl형이지만 col_types를 text로 정해준 data6의 column의 경우 chr형으로 자료형이 바뀐것을 볼 수 있습니다.
na : NA로 인식할 값을 정해줄 수 있습니다 기본은 빈값을 NA로 인식합니다.
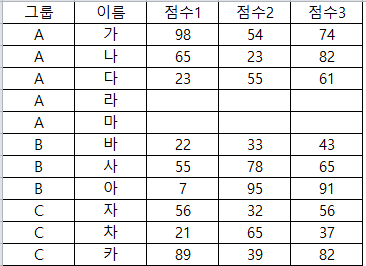
위의 data를 불러오면
data7 <- read_excel("C:/Users/user/Desktop/R블로그/read excel, read csv/RAW DATA.xlsx",sheet=3,na="")
data7
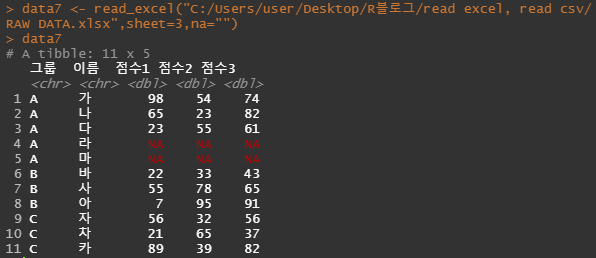
NA로 불러오는것을 확인할 수 있습니다.
trim_ws : data 앞 뒤에 띄어쓰기가 있으면 이를 제거 하고 불러오는 인자입니다.
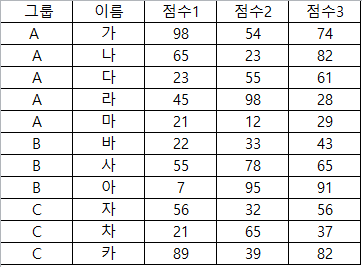
1행1열에는 문자앞에 띄어쓰기, 2행1열에는 문자뒤에 띄어쓰기를 입력하고 불러와보겠습니다.
data8 <- read_excel("C:/Users/user/Desktop/R블로그/read excel, read csv/RAW DATA.xlsx",sheet=4,trim_ws=F)
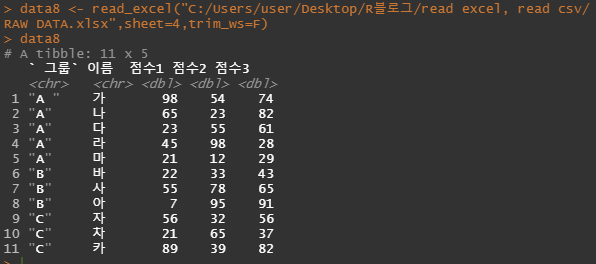
띄어쓰기가 그대로 들어있는것을 볼 수 있습니다.
default는 True이기때문에 띄어쓰기는 제거하고 불러옵니다.
skip : 처음 몇개의 행을 skip하고 불러올지 정할 수 있습니다.
data9 <- read_excel("C:/Users/user/Desktop/R블로그/read excel, read csv/RAW DATA.xlsx",sheet=4,skip=3)
data9

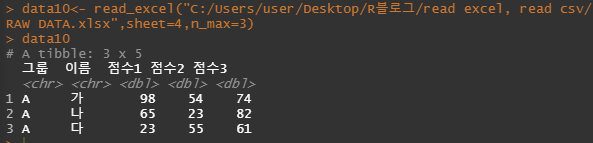
n_max : 최대 몇번째 행까지 불러올지 정할 수 있습니다.
data10<- read_excel("C:/Users/user/Desktop/R블로그/read excel, read csv/RAW DATA.xlsx",sheet=4,n_max=3)
data10
'R' 카테고리의 다른 글
| R ) dplyr 패키지 살펴보기 ( filter, select, arrange, mutate, summarise, group_by, %>% (파이프연산자) ) in r -2 (1) | 2021.09.02 |
|---|---|
| R ) dplyr 패키지 살펴보기 ( filter, select, arrange, mutate, summarise, group_by, %>% (파이프연산자) ) in r (1) | 2021.09.01 |
| R ) 데이터(data) 전반적 구조 파악하기 head, tail, View, dim, str, summary in r (1) | 2021.08.31 |
| R ) CSV 파일 불러오기 read.csv in r (0) | 2021.08.29 |
| str_split 문자열 나누기 in r (1) | 2021.08.21 |




댓글