data를 받으면 가장먼저 data의 전반적 구조에 대해 파악해야 합니다.
이때 사용하는 기능들을 알아보겠습니다.
이번에 사용할 data는 R 내장 data인 iris data를 이용하여 알아보도록 하겠습니다.
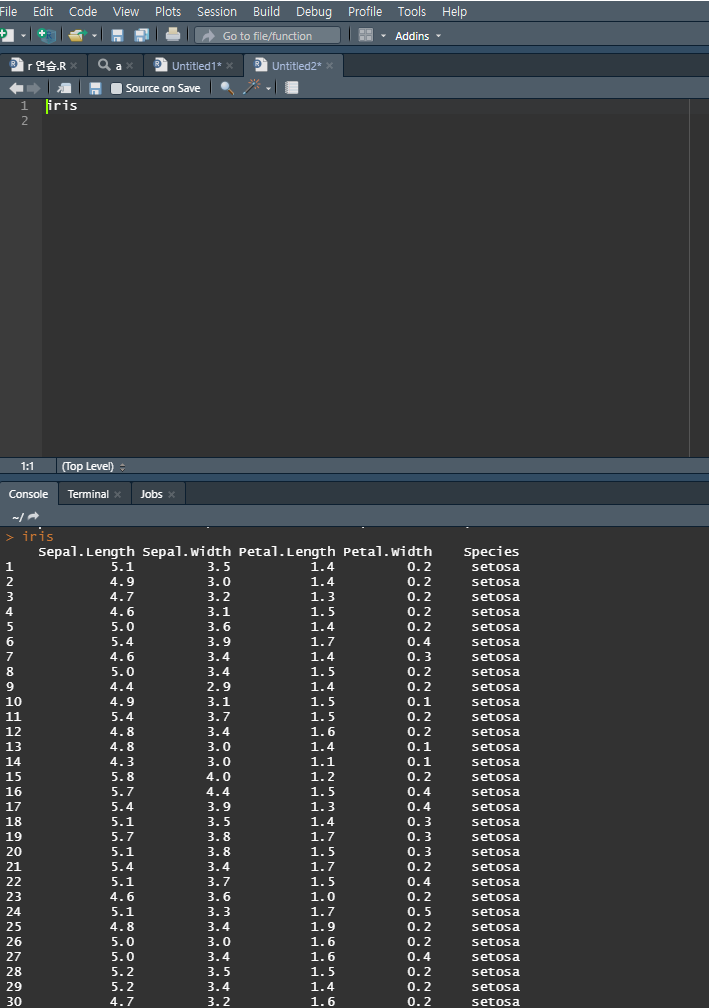
이번에 알아볼 함수는
head, tail, View, dim, str, summary 입니다
먼저 각각 data의 기능을 설명하겠습니다.
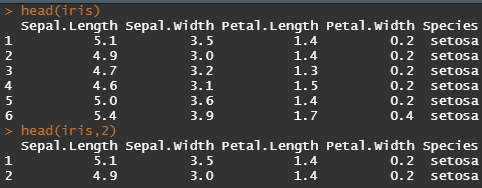
head() : 벡터, 매트릭스, 데이터프레임의 처음부터 정해진 수까지의 data를 반환합니다. 디폴트 값으로 처음 5개의 값을 반환합니다.
head(iris)
head(iris,2)
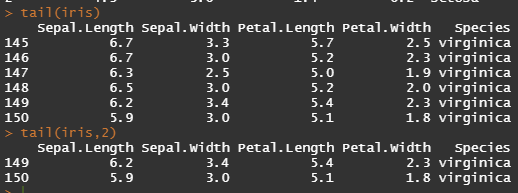
tail() : 벡터, 매트릭스, 데이터프레임의 마지막부터 정해진 수까지의 data를 반환합니다. 디폴트 값으로 처음 5개의 값을 반환합니다.
tail(iris)
tail(iris,2)
View() : data를 뷰어를 통해 볼 수있습니다. data 양이 많으면 모두 나오지 않고 일부분만 나오게 됩니다.
View(iris)

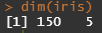
dim : data의 dimension을 반환합니다. 즉, 행과 열의 갯수를 반환합니다.
dim(iris)
str : data의 구조를 나타내고 data의 속성, 내용을 압축하여 디스플레이해줍니다
str(iris)

summary : data의 요약 통계량을 산출합니다.
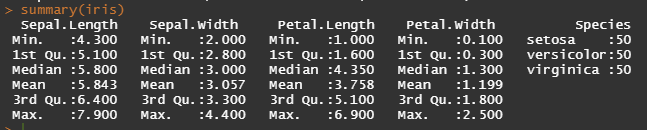
간단하게 통계량의 의미를 살펴보겠습니다.
min : 최소값
1st Qu : 1사분위수 (하위 25% 지점에 위치하는 값)
Median : 중앙값
Mean : 평균
3rd Qu : 3사분위수 (하위 75% 지점에 위치하는 값)
Max : 최대값
또한 num type column들은 통계량이 나오지만 factor type column은 범주의 개수가 나타나게 됩니다.
위 함수들은 data를 다룸에 앞서 data의 전반적 구조를 파악하는데 도움을 주는 함수들입니다.
'R' 카테고리의 다른 글
| R ) dplyr 패키지 살펴보기 ( filter, select, arrange, mutate, summarise, group_by, %>% (파이프연산자) ) in r -2 (1) | 2021.09.02 |
|---|---|
| R ) dplyr 패키지 살펴보기 ( filter, select, arrange, mutate, summarise, group_by, %>% (파이프연산자) ) in r (1) | 2021.09.01 |
| R ) CSV 파일 불러오기 read.csv in r (0) | 2021.08.29 |
| read_excel로 외부 Data 불러오기 in r (0) | 2021.08.22 |
| str_split 문자열 나누기 in r (1) | 2021.08.21 |




댓글