R에서 병렬처리 함수인 mclapply에 관해 알아보려고 합니다.
mclapply는 코드를 처리할때 병렬로 처리하여 코드 처리시간을 단축 시킬 수 있는 코드입니다.
해당함수는 윈도우에서는 사용하지 못하는것으로 알고있고 mac이나 linux에서 사용할 수 있는 것으로 알고 있습니다.
parallel 패키지에 있는 함수 입니다.
mclapply(X=설정값,mc.cores=설정값,FUN=설정값) 의 인자를 갖고 있습니다.
mc.cores에는 detectCores() 함수로 사용가능한 core수를 확인하고 적당한 값을 넣어주면 됩니다.
모든 core를 입력하면 다른 작업을 못 할 수도 있으므로 1~2개 작은 core를 사용하는것이 좋은것 같습니다.
for문과 비교하여 얼마나 빠른지 확인해 보도록 하겠습니다.
먼저 크기가 큰 data를 만들어주기 위해 iris를 data를 여러번 붙여
row : 153600개
column : 32개
인 data를 만들어 주겠습니다. 단순히 iris data를 cbind 8번, rbind 1024번 붙여준 data입니다. 간단하게 하기위해 "Species" column은 제외했습니다.


먼저 for문을 이용해 측정한 시간입니다.
간단하게 row별로 sum을 하는 함수를 실행시켰습니다.
start1 <- Sys.time()
for(i in 1:nrow(df)){
sum(df[i,])
print(i)
}
end1 <- Sys.time()
end1-start1
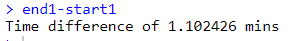
1.102426분이 걸렸습니다 66.14556초가 걸렸습니다.
다음으로 core 3개를 이용해 처리한 코드입니다.
start2 <- Sys.time()
mclapply(X=1:nrow(df),mc.cores=3,function(x){
sum(df[x,])
return(x)
})
end2 <- Sys.time()
end2-start2

21.60411초가 걸렸습니다.
다음으로 5개의 core를 이용한 코드입니다.
start3 <- Sys.time()
mclapply(X=1:nrow(df),mc.cores=5,function(x){
sum(df[x,])
return(x)
})
end3 <- Sys.time()
end3-start3

15.12438초가 걸렸습니다.
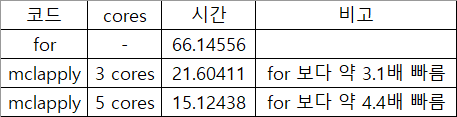
core의 개수만큼 비례해서 빨라지는것은 아니지만... 위와 같이 병렬 처리 함수를 사용한 것이 훨씬 빠른것을 볼 수 있습니다.
작은 data에서는 for문이나 apply를써도 상관이 없겠지만 big data를 다룰때는 mclapply를 사용하는것도 나쁘지 않아보입니다.
'R' 카테고리의 다른 글
| R ) as.formula 활용하기 formula 인자 변경하면서 반복문 사용 (0) | 2022.11.30 |
|---|---|
| R ) future함수 multisession 병렬처리 알아보기 in r (0) | 2022.11.16 |
| R ) NA를 이전 행 값으로 채우기 na.locf()함수 in r (0) | 2022.11.12 |
| R ) separate_rows() 셀 분할하고 행으로 만들기 in r (1) | 2022.10.29 |
| R ) transpose t( )함수 알아보기 [행 - 열 변환, 행/열 바꾸기] in r (1) | 2022.10.29 |




댓글