728x90
728x90
통계 공부한것을 기록하는 3번째 입니다.
분산 : 관측값이 평균으로부터 떨어져 있는 크기의 평균을 의미합니다.
data가 평균으로부터 퍼져있는 정도를 알 수 있습니다.
var(iris$Sepal.Length)

표준편차 : 분산의 양의 제곱근입니다.
분산은 편차 제곱합의 평균이므로 원래 데이터와 척도가 다르다 그래서 data의 퍼진정도를 파악할때는 분산보다 표준편차로 보는게 더 좋다.
sd(iris$Sepal.Length)

중위수절대편차 : 개별 관측값에서 중위수를 뺀 편차의 절대값에 대한 중위수에 상수를 곱한것 표준편차보다 강력한 통계량으로 사용 (평균의 영향을 덜받아서 인가...?)
abs(iris$Sepal.Length-med) %>% median()*1.4826
mad(iris$Sepal.Length)

위 코드가 mad함수의 계산법이다 1.4826의 의미는 공부를 해봐야 할듯...?
중위수절대편차를 이용해 outlier를 제거하는 방법도 있다.
which(abs((iris$Sepal.Length-med)/mad)>2)

위와 같이 계산하여 2를 넘는 것은 outlier로 보고 제외 하는 것이다.
왜도 : 확률밀도곡선의 중심이 치우친 정도를 알 수 있다.
양수면 왼쪽 음수면 오른쪽으로 치우친 분포이며 정규분포의 왜도는 0이다
첨도 : 확률밀도곡선의 봉우리가 뾰족한지 완만한지 여부를 알 수 있다.
정규분포할때의 첨도는 3이고 3보다 크면 뾰족, 작으면 완만으로 한다.
install.packages("moments")
library(moments)
skewness(iris$Sepal.Length)
kurtosis(iris$Sepal.Length)
hist(iris$Sepal.Length, breaks=20, probability=TRUE)
lines(density(iris$Sepal.Length))
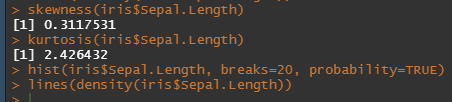
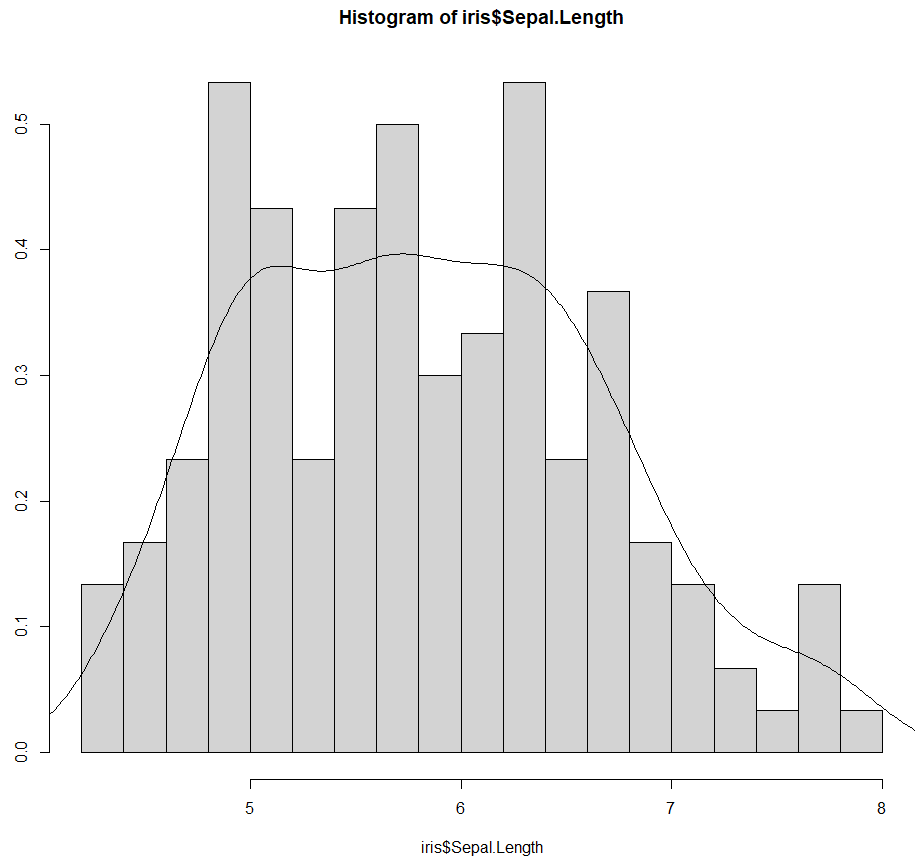
위와 같이 나타난다.
728x90
728x90




댓글