future함수의 multisession에 대해 알아보려고 합니다...
솔직히 요게 어떤건지 확실히는 모르겠습니다...
그런데 core여러개를 이용해 R의 multisession을 만들고 각각의 future를 병렬 실행해 빠르게 data의 결과를 얻을 수 있다는 것은 알것 같습니다... 또한 다른 session에서 코드처리를 진행하기 때문에 내가 현재 사용하고 있는 session에서는 계속해서 코드를 처리할 수 있는것 같습니다.
더 자세히 알게되면 업데이트 해야겠습니다...
앞서 말했듯 future함수의 multisession을 이용해 data를 더욱 빠르게 처리할 수 있습니다.
해당 함수는 future 패키지에 있는 함수 입니다.
예시를 보면서 얘기해 보겠습니다.
해당 함수의 실습을 위해 iris data를 여러개 붙여 큰 data로 만들었습니다.

간단하게 코드를 처리하면서 시간이 얼마나 걸리는지 알아보겠습니다..
3개의 data table을 row별 sum을 진행했습니다.
먼저 for만 사용한 경우 입니다.
start1_2 <- Sys.time()
for(i in 1:length(df_list)){
temp <- df_list[[i]]
for(j in 1:nrow(temp)){
sum(temp[j,])
print(paste0(i,"_",j))
}
} end1_2 <- Sys.time()
end1_2-start1_2

4.548205분 // 272.8923초 걸렸습니다.
다음으로 future함수를 이용해 병렬진행한 경우 입니다.
future의 경우 2개의 형태로 사용할 수 있어 2개형태 모두 적겠습니다.
availableCores() 사용가능한 코어 확인
plan(multisession, workers = 4) 사용할 코어 정하기
test_future1_2_list <- listenv::listenv()
start2_2 <- Sys.time()
for(i in 1:length(df_list)){
temp <- df_list[[i]]
test_future1_2_list[[i]] <- future({
for(j in 1:nrow(temp)){
sum(temp[j,])
print(j)
}
})
print(i)
}
while(TRUE){
if(sum(resolved(test_future1_2_list))==3){
end2_2<- Sys.time()
break
}
}
end2_2-start2_2
위 코드로 진행하면

1.100988분 // 67.160268초가 걸립니다.
또다른 형태의 future를 사용하면
test_future2_2_list <- listenv::listenv()
start3_2 <- Sys.time()
for(i in 1:length(df_list)){
temp <- df_list[[i]]
test_future2_2_list[[i]] %<-% {
for(j in 1:nrow(temp)){
sum(temp[j,])
print(j)
}
} %plan% multisession
print(i)
}
while(TRUE){
if(sum(resolved(test_future2_2_list))==3){
end3_2<- Sys.time()
break
}
}
end3_2-start3_2

1.081089분 // 64.86534초가 걸립니다.
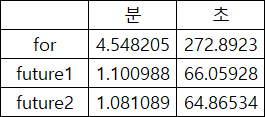
시간을 비교해보면 multisesseion을 이용해 처리한것이 3배정도 빠른것으로 확인됐습니다.
big data를 다룰때 사용하면 유용할것 같습니다.
'R' 카테고리의 다른 글
| R ) column 추가하기 data.table, data.frame in r (0) | 2022.12.16 |
|---|---|
| R ) as.formula 활용하기 formula 인자 변경하면서 반복문 사용 (0) | 2022.11.30 |
| R ) 병렬처리, 병렬함수 mclapply 알아보기 in r (0) | 2022.11.15 |
| R ) NA를 이전 행 값으로 채우기 na.locf()함수 in r (0) | 2022.11.12 |
| R ) separate_rows() 셀 분할하고 행으로 만들기 in r (1) | 2022.10.29 |




댓글