안녕하세요~
오늘은 R을 이용해 data의 결측치를 처리하는 법에 대해 보겠습니다.
여러방법이 있겠지만.... map함수를 이용해 data의 결측치를 처리해 보겠습니다.
map함수는 purrr 라이브러리에 있는 함수 입니다.
기본형은
map(.x=data,.f=f,...)
입니다.
.x에는 다루고자 하는 data가 들어가고 .f에는 적용하고자하는 function을 넣으면됩니다.
미리 만들어져있는 mean, max등의 함수도 넣을 수 있지만function(x)를 이용해 사용자가 함수를 정의해 줄 수도 있습니다.
오늘 사용한 toy data는

df <- data.frame(col1=c(1,NA,2,NA,3,4),
col2=c(5,6,7,NA,NA,NA),
col3=c(NA,8,9,NA,NA,10))
df

입니다
col1 : 2
col2 : 3
col3 : 3
개의 결측치가 있습니다.
이 결측치에 avg값을 넣어 결측치를 처리해 보겠습니다.
map(.x=df,.f=function(x){
ifelse(is.na(x),mean(x,na.rm=T),x)
})

map함수를 이용해 NA로 된 결측치를 각행의 평균값으로 채워주었습니다.
하지만 map은 list로 반환을 하기 때문에 dataframe으로 반환을 해주는 map_df를 쓰도록 하겠습니다.
map_df(.x=df,.f=function(x){
ifelse(is.na(x),mean(x,na.rm=T),x)
})
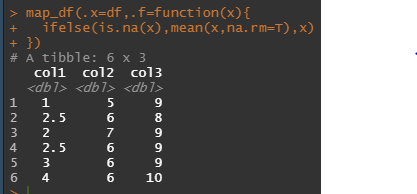
map_df를 이용하면 위와 같이 dataframe으로 data를 반환 받을 수 있습니다. 정확히 말하자면 tibble의 형태로 반환을 하지만....(저도 dataframe과 tibble의 정확한 차이를 모르겠네요...data의 형식 차이고 tibble이 더 최근에 나온 data의 형식이란것과 둘사이에 적용되는 함수가 다를 수 있다는것.. 밖에는...)
tibble을 dataframe으로 바꾸어 사용하고 싶다면 as.data.frame으로 형식을 바꾸어 주어도 됩니다.
여기선 굳이 바꿀필요가 없기에 그냥하겠습니다.
다시 돌아와서..
위와 같은 방법으로도 결측치를 채울 수 있지만 좀 더 눈으로 보기편하게..? 나타내 보았습니다.
map_df(.x=df,.f=function(x){
x[is.na(x)] <- mean(x,na.rm=T)
x[!is.na(x)] <- x
})
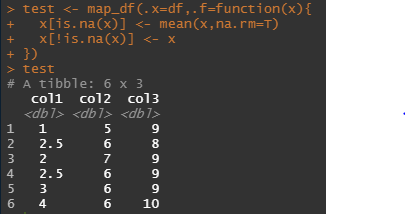
조금 더 직관적인가요,,,?
위와는 조금 다르지만 동일하게 작동하는 것을 볼 수 있습니다.
이런 방법을 사용하면 결측치에 mean, max, min, median등의 값으로 채워넣을 수 있습니다.
'R' 카테고리의 다른 글
| R ) 행렬 알아보기 matrix in r (0) | 2022.04.01 |
|---|---|
| R ) list 자료형 in r (0) | 2022.04.01 |
| R ) 통계값 column추가 하기 in r (0) | 2022.03.30 |
| R ) 논리 연산자 in r ( &, |, ! ) in r (0) | 2021.09.30 |
| R ) 비교 연산자 알아보기 in r >, >=, <, <=, ==, != in r (0) | 2021.09.27 |




댓글